Codex 配置说明
继续在主页面展示完整 HTML 渲染内容,覆盖 config.toml、AGENTS.md、MCP、Skills 与 Subagents。
本页现在分成三个同级模块:Codex 配置说明、LobeHub 接入说明、CC Switch 接入说明。
目录中这三个模块都是一级条目;每个模块下方再展开各自的子章节。
LobeHub 部分只保留适合入门用户的 API 配置教学,并补充常见功能概览。
这一页现在明确分成三个同级模块:Codex 配置说明、LobeHub 接入说明、CC Switch 接入说明。每个模块下方再展开各自的子章节。
继续在主页面展示完整 HTML 渲染内容,覆盖 config.toml、AGENTS.md、MCP、Skills 与 Subagents。
补全安装、首次配置、Provider 切换,以及 Claude Code、OpenCode、OpenClaw 的接入说明与本地图示。
已补全入门用户最常用的 API 配置方法,强调按模型公司选择 Provider,并补充官方 Web、自建 Web 与功能概览。
这一组内容专门讲 Codex 本体的配置逻辑。下方五项都属于 Codex 的子章节:先从 config.toml 与 AGENTS.md 入手,再看 MCP、Skills 与 Subagents。
以这个配置示例作为起点,本节将会介绍 Codex 从 config.toml 中读取的大部分常用配置项。
请参考下方代码块,仅把你需要的部分复制到 ~/.config/codex/config.toml 中,并根据需要修改配置项的值。
model_provider = "newapi" # 使用 API 接入时必填,用于选择模型提供商,可以根据你的喜好命名
model = "gpt-5.4" # 必填,模型名称,具体可用的模型取决于中转站支持的模型,在 Codex 内建议使用 GPT 系列模型以获得更好的体验
model_context_window = 1000000 # 非必填,模型上下文窗口大小,单位为 token,建议设置为和模型匹配的最大值
model_auto_compact_token_limit = 400000 # 非必填,模型自动压缩 token 阈值,建议根据实际体验调整,过低可能导致频繁压缩,过高可能导致上下文过大时模型幻觉。必须小于上下文窗口大小
model_reasoning_effort = "xhigh" # 非必填,模型推理努力程度,影响模型在生成时的思考深度和细致程度,通常有 "low", "medium", "high", "xhigh" 四个级别,级别越高模型生成的内容越详细和深入,但也可能更慢
disable_response_storage = true # 非必填,是否禁用响应存储,启用后 Codex 将不会保存模型的响应内容,以到达提高隐私保护的目的
model_instructions_file = "prompts/orchestrator.md" # 非必填,模型指令文件路径,指令文件是一个 Markdown 文件,包含了模型的系统指令和行为规范,可以根据需要进行定制
plan_mode_reasoning_effort = "xhigh" # 非必填,计划模式下模型推理努力程度
service_tier = "fast" # 非必填,服务层级,影响模型的响应速度和可用性,选择 fast 时模型响应更快,但费率为 2 倍
model_supports_reasoning_summaries = true # 非必填,模型是否支持推理总结功能,如果支持,Codex 将在模型生成过程中定期生成推理总结,以帮助模型保持上下文连贯和减少幻觉
sandbox_mode = "danger-full-access" # 非必填,沙箱模式,影响 Codex 执行代码和访问系统资源的权限,选择 "danger-full-access" 时 Codex 将拥有完全的系统访问权限,适合在安全的环境中使用以发挥 Codex 的全部能力,但在不受信任的环境中可能存在安全风险
preferred_auth_method = "apikey" # 非必填,首选认证方式,影响 Codex 连接模型提供商时使用的认证方式,选择 "apikey" 时 Codex 将使用 API 密钥进行认证,选择 "oauth" 时 Codex 将使用 OAuth 进行认证,具体可用的认证方式取决于模型提供商的支持
personality = "pragmatic" # 非必填,Codex 的人格设定,影响 Codex 在与用户交互时的语气和风格,选择 "pragmatic" 时 Codex 将以务实和直接的方式进行交流,适合技术讨论和问题解决
[features]
fast_mode = true # 非必填,是否启用快速模式,启用后 Codex 将优先使用更快的模型和响应策略,以提高响应速度,但费率会变为 2 倍
multi_agent = true # 非必填,是否启用多代理功能,启用后 Codex 将能够同时管理和协调多个智能体,以处理更复杂的任务和场景
js_repl = true # 非必填,是否启用 JavaScript REPL 功能,启用后 Codex 将能够执行 JavaScript 代码片段,并返回结果,适合进行前端开发和调试
guardian_approval = true # 非必填,是否启用 Guardian 审批功能,启用后 Codex 将在执行敏感操作时请求用户批准,以增强安全性和控制力
[model_providers.newapi] # 模型提供商配置,"newapi" 是一个示例名称,可以根据你的喜好命名,但必须与上面 model_provider 配置项的值匹配
name = "newapi" # 必填,模型提供商名称,必须与上面 model_provider 配置项的值匹配
base_url = "https://new.saika.qzz.io/v1" # 必填,模型提供商 API 基础 URL,根据你选择的模型提供商进行设置
wire_api = "responses" # 非必填,模型提供商 API 类型,影响 Codex 与模型提供商交互的方式,目前仅支持 "responses"
stream_max_retries = 99 # 非必填,流式响应最大重试次数,影响 Codex 在与模型提供商通信时的鲁棒性,设置为较高的值可以在网络不稳定或模型提供商出现问题时增加成功率,但也可能导致更长的等待时间
[mcp_servers.ssh] # 非必填,示例 MCP Server 配置,ssh mcp 可用于通过 SSH 协议连接远程服务器并执行命令
args = ["-y", "@fangjunjie/ssh-mcp-server", "--config-file", "c:\\path-to-your-config\\ssh-config.json"] # 可选,启动 MCP Server 的命令行参数,这里使用了一个示例的 SSH MCP Server,并指定了一个配置文件路径,根据实际情况进行修改
command = "npx" # 可选,启动 MCP Server 的命令,这里使用 npx 来运行一个 npm 包,你也可以直接指定一个可执行文件
startup_timeout_sec = 60 # 可选,MCP Server 启动超时时间,单位为秒,根据实际情况进行调整
[mcp_servers.ssh.tools.list-servers] # 非必填,ssh MCP Server 的工具配置,这里配置了一个名为 list-servers 的工具,并设置了审批模式为 "approve",表示在 Codex 执行这个工具时需要用户批准
approval_mode = "approve"
[mcp_servers.ssh.tools.execute-command]
approval_mode = "approve"
[mcp_servers.ssh.tools.download]
approval_mode = "approve"
[mcp_servers.ssh.tools.upload]
approval_mode = "approve"
[mcp_servers.filesystem] # 非必填,示例 MCP Server 配置,filesystem mcp 可用于访问本地文件系统并执行文件操作
command = "npx" # 可选,启动 MCP Server 的命令,这里使用 npx 来运行一个 npm 包,你也可以直接指定一个可执行文件
args = ["-y", "@modelcontextprotocol/server-filesystem", "c:\\path-to-your-workspace"] # 可选,启动 MCP Server 的命令行参数,这里使用了一个示例的 filesystem MCP Server,并指定了一个目录路径,根据实际情况进行修改
startup_timeout_sec = 60
[mcp_servers.context7] # 非必填,示例 MCP Server 配置,context7 mcp 可用于提供一个上下文管理平台,帮助模型更好地理解和利用上下文信息
command = "npx" # 可选,启动 MCP Server 的命令,这里使用 npx 来运行一个 npm 包,你也可以直接指定一个可执行文件
args = ["-y", "@upstash/context7-mcp"] # 可选,启动 MCP Server 的命令行参数,这里使用了一个示例的 context7 MCP Server
startup_timeout_sec = 60
[mcp_servers.playwright_executeautomation] # 非必填,示例 MCP Server 配置,playwright_executeautomation mcp 可用于通过 Playwright 自动化浏览器操作,适合进行前端测试和自动化任务
command = "npx" # 可选,启动 MCP Server 的命令,这里使用 npx 来运行一个 npm 包,你也可以直接指定一个可执行文件
args = ["-y", "@executeautomation/playwright-mcp-server"] # 可选,启动 MCP Server 的命令行参数,这里使用了一个示例的 Playwright ExecuteAutomation MCP Server,根据实际情况进行修改
startup_timeout_sec = 60
[mcp_servers.sequentialthinking] # 非必填,示例 MCP Server 配置,sequentialthinking mcp 可用于提供顺序思维功能,帮助模型更好地处理复杂的逻辑推理任务
command = "npx" # 可选,启动 MCP Server 的命令,这里使用 npx 来运行一个 npm 包,你也可以直接指定一个可执行文件
args = ["-y", "@modelcontextprotocol/server-sequential-thinking"] # 可选,启动 MCP Server 的命令行参数,这里使用了一个示例的 sequentialthinking MCP Server,根据实际情况进行修改
enabled = true # 可选,是否启用这个 MCP Server,根据实际需要进行设置
startup_timeout_sec = 60
[mcp_servers.memory] # 非必填,示例 MCP Server 配置,memory mcp 可用于提供内存管理功能
command = "node" # 可选,启动 MCP Server 的命令,这里使用 node 来运行一个 JavaScript 文件,你也可以指定其他可执行文件
args = ["C:\\path-to-your-workspace\\index.js"] # 可选,启动 MCP Server 的命令行参数,这里指定了一个 JavaScript 文件路径,根据实际情况进行修改
enabled = true
startup_timeout_sec = 60
[mcp_servers.memory.env] # 非必填,memory MCP Server 的环境变量配置,这里设置了一个 MEMORY_FILE_PATH 环境变量,指向一个 JSONL 文件路径,用于存储模型的记忆数据,根据实际情况进行修改
MEMORY_FILE_PATH = "C:\\path-to-your-workspace\\memory.jsonl"
[mcp_servers.memory.tools.search_nodes] # 非必填,memory MCP Server 的工具配置,这里配置了一个名为 search_nodes 的工具,并设置了审批模式为 "approve",表示在 Codex 执行这个工具时需要用户批准
approval_mode = "approve"
[windows] # Windows 专用配置项
sandbox = "elevated" # Windows 必填项,沙箱模式,影响 Codex 在 Windows 系统上的权限和安全性,选择 "elevated" 时 Codex 将以提升的权限运行,适合在受信任的环境中使用以发挥 Codex 的全部能力,但在不受信任的环境中可能存在安全风险
[agents] # 代理配置,定义了 Codex 中可用的智能体,每个智能体都有自己的职责和能力,可以根据需要启用和配置不同的智能体
max_threads = 8 # 可选,最大线程数,根据实际需要进行设置
max_depth = 2 # 可选,最大递归深度,影响智能体在处理任务时的递归调用深度,设置为较高的值可以让智能体更深入地分析和解决问题,但也可能导致更长的处理时间和更高的资源消耗
job_max_runtime_seconds = 14400 # 可选,智能体单个任务的最大运行时间,单位为秒,根据实际需要进行设置,过短可能导致智能体无法完成复杂任务,过长可能导致资源占用过久
[agents.explorer] # Explorer 智能体配置,负责快速理解代码库、映射结构和识别需要深入分析的部分
description = "Rapidly understand a codebase, map structure, and identify what needs deeper analysis." # 可选,智能体描述,提供了一个简短的描述,说明这个智能体的主要职责和能力,可以根据实际情况进行修改
config_file = "agents/explorer.toml" # 可选,智能体配置文件路径,这个文件可以包含这个智能体特定的配置项,根据实际情况进行修改
nickname_candidates = ["Explorer"] # 可选,智能体昵称候选列表,提供了一组昵称选项,Codex 在与用户交互时可能会使用这些昵称来称呼这个智能体,可以根据实际情况进行修改
[agents.analyzer] # Analyzer 智能体配置,负责深入诊断问题、追踪根本原因,并提供有证据的影响解释
description = "Diagnose problems deeply, trace root causes, and explain impact with evidence." # 可选,智能体描述,提供了一个简短的描述,说明这个智能体的主要职责和能力,可以根据实际情况进行修改
config_file = "agents/analyzer.toml" # 可选,智能体配置文件路径,这个文件可以包含这个智能体特定的配置项,根据实际情况进行修改
nickname_candidates = ["Analyzer"] # 可选,智能体昵称候选列表,提供了一组昵称选项,Codex 在与用户交互时可能会使用这些昵称来称呼这个智能体,可以根据实际情况进行修改
请注意,这只是一个示例配置。实际使用时你可能需要根据自己的需求和环境进行调整。建议逐项了解每个配置项的作用和影响,再决定最终配置。
API Key 将会存储在 ~/.codex/auth.json 文件中,需要修改 API Key 时请直接编辑该文件。
Codex 在执行任何工作前都会读取 AGENTS.md 文件。通过把全局注入与项目级覆盖分层管理,无论你打开哪个工作区,都能以一致的预期开始每项任务。
Codex 在启动时会建立一条指令链,查找顺序如下:
一旦文件总大小达到 project_doc_max_bytes 定义的限制(默认 32 KiB),Codex 就会跳过空文件并停止继续添加。当达到上限时,请提高限制,或在嵌套目录中拆分指令文件。
你可以在 Codex 主目录中创建持久默认设置,这样每个项目都会继承你的全局指令。
## 工作准则
- 以务实和直接的方式与用户交流,适合技术讨论和问题解决;
- 在不确定时提出澄清问题,以更好地理解用户的需求;
- 优先提供简洁的解决方案,除非用户要求更详细的解释。项目级文件可以让 Codex 在继承全局默认设置的同时了解仓库规范。
## 仓库规范
- 代码库使用 TypeScript 编写,遵循 Airbnb 的编码规范;
- 项目使用 monorepo 结构,包含多个包和共享库;
- 主要依赖项包括 React、Node.js 和 Express。## 支付模块准则
- 支付模块使用 Python 编写,遵循 PEP 8 编码规范;
- 支付模块必须实现严格的错误处理和日志记录,以确保安全性和可维护性。Model Context Protocol(MCP)会把模型与工具、上下文连接起来。通过它,Codex 可以调用工具完成实际工作,而不只是与你对话。Codex 支持 STDIO 和 Streamable HTTP 两种类型的 MCP Server。你可以在 config.toml 中配置多个 MCP Server,并在 AGENTS.md 或 Instructions 中指定智能体该使用哪个 MCP Server 访问特定工具集。
上述示例配置里包含了 SSH、Filesystem、Context7、Playwright ExecuteAutomation、SequentialThinking、Memory 等 MCP Server。你可以根据实际需要配置自己的 MCP Server,并在智能体配置中启用它们来扩展 Codex 的能力。每个 MCP Server 都有各自的配置项,包括启动命令、命令行参数、启动超时时间,以及工具审批模式等。请根据实际情况进行调整。
或者,你也可以把开源 MCP Server 的 GitHub 仓库地址提供给 Codex,让 Codex 自行安装并完成基础配置。
使用 Skills 可以扩展 Codex 在特定任务上的能力。一个 Skill 可以打包指令、资源和可选脚本,让 Codex 更稳定地遵循既定工作流。
Skills 是用于描述可复用工作流的编写格式。它通过逐步公开来管理上下文:Codex 会先读取每个 Skill 的元数据(名称、描述、文件路径,以及来自 agents/openai.yaml 的可选信息),只有在确定要使用某个 Skill 时,才会加载完整的 SKILL.md 说明。一个 Skill 本质上是一个目录,目录中至少包含一个 SKILL.md 文件,也可以附带脚本和参考资料。SKILL.md 必须包含 name 和 description。
Codex 可以通过两种方式激活 Skills:
由于隐式匹配依赖 description,因此在编写描述时应明确 Skill 的适用范围与边界。
首先使用内置创建器 $skill-creator,它会询问这个 Skill 的作用、触发时机,以及是否只使用指令或额外包含脚本。默认情况下仅包含指令。
你也可以手动创建一个包含 SKILL.md 文件的文件夹:
---
name: skill-name
description: Explain exactly when this skill should and should not trigger.
---
Skill instructions for Codex to follow.Codex 会自动检测 Skills 的变化。如果没有出现更新,请重启 Codex。
Codex 可以从工作区、用户、管理员和系统位置读取 Skills。对于工作区,Codex 会扫描从当前工作目录到工作区根目录之间每一级目录中的 .agents/skills。如果两个 Skill 共享相同的 name,Codex 不会合并它们;它们都会出现在技能选择器中。
Codex 可以通过并行生成专门代理来运行 Subagent 工作流,再在一个响应中汇总结果。这对于高度并行的复杂任务特别有用,例如工作区探索或多步骤功能实施。
通过 Subagent 工作流,你还可以定义自己的自定义 Agent,并根据不同任务使用不同的模型配置与指令。
Codex 只会在你明确要求时产生 Subagents。由于每个 Subagent 都要独立执行自己的模型与工具工作,因此 Subagents 工作流的 token 消耗通常高于类似的单 Agent 工作流。
你可以为每个 Subagent 定义专用的 config.yaml 和 model_instruction_file,覆盖默认模型指令,让不同类型的 Subagent 更适合各自任务。比如在工作区探索型 Subagent 中,你可能希望使用更快的模型和更简洁的指令,以便快速扫描代码库结构;而在问题分析型 Subagent 中,你可能希望使用更强的模型和更详细的指令,以便更深入地理解根本原因与影响范围。
这一组内容面向初学者,重点只讲 LobeHub 里最常用、最容易上手的 API 配置路径。原则是:用户想用哪家公司的模型,就只开启对应公司的 Provider;本站没有提供的默认 Provider 建议关闭,避免混淆。
对入门用户来说,最核心的只有一件事:先进入 Settings → Language Model,再在 AI Providers 中只开启你真正要用的 Provider。
根据 LobeHub 官方文档,模型服务商的配置都集中在 Settings → Language Model。基础流程可以概括为:
官方多 Provider 文档明确说明:每个 Provider 都在 Settings → Language Model 中配置;如果你使用代理或自建端点,可以额外填写自定义 Base URL。

不要一上来把所有 Provider 全开。对入门用户来说,Provider 开得越多,模型选择越乱,排错也越麻烦。
| 使用目标 | 建议启用 | 建议关闭 |
|---|---|---|
| 想用 OpenAI / GPT / o 系列 | 只启用 OpenAI | Google Gemini、Azure OpenAI、Anthropic Claude 等当前不用的 Provider 先关掉 |
| 想用 Claude 系列 | 只启用 Anthropic Claude | OpenAI、Google Gemini 等当前不用的 Provider 先关掉 |
| 想分别用不同公司的模型 | 按公司逐个启用,例如 OpenAI、Anthropic Claude 分开开 | 本站没有提供或你暂时不用的 Provider 先关掉 |
对本站 https://new.saika.qzz.io 的建议写法很简单:想用哪家公司的模型,就去开哪家公司的 Provider,并在那一项里填写 Key 与 Base URL。
入门阶段不要追求“全开”。Provider 开得越多,模型筛选越乱,排错成本也越高。
适用于想使用 GPT-4o、GPT-4.1、o 系列等 OpenAI 家族模型的用户。
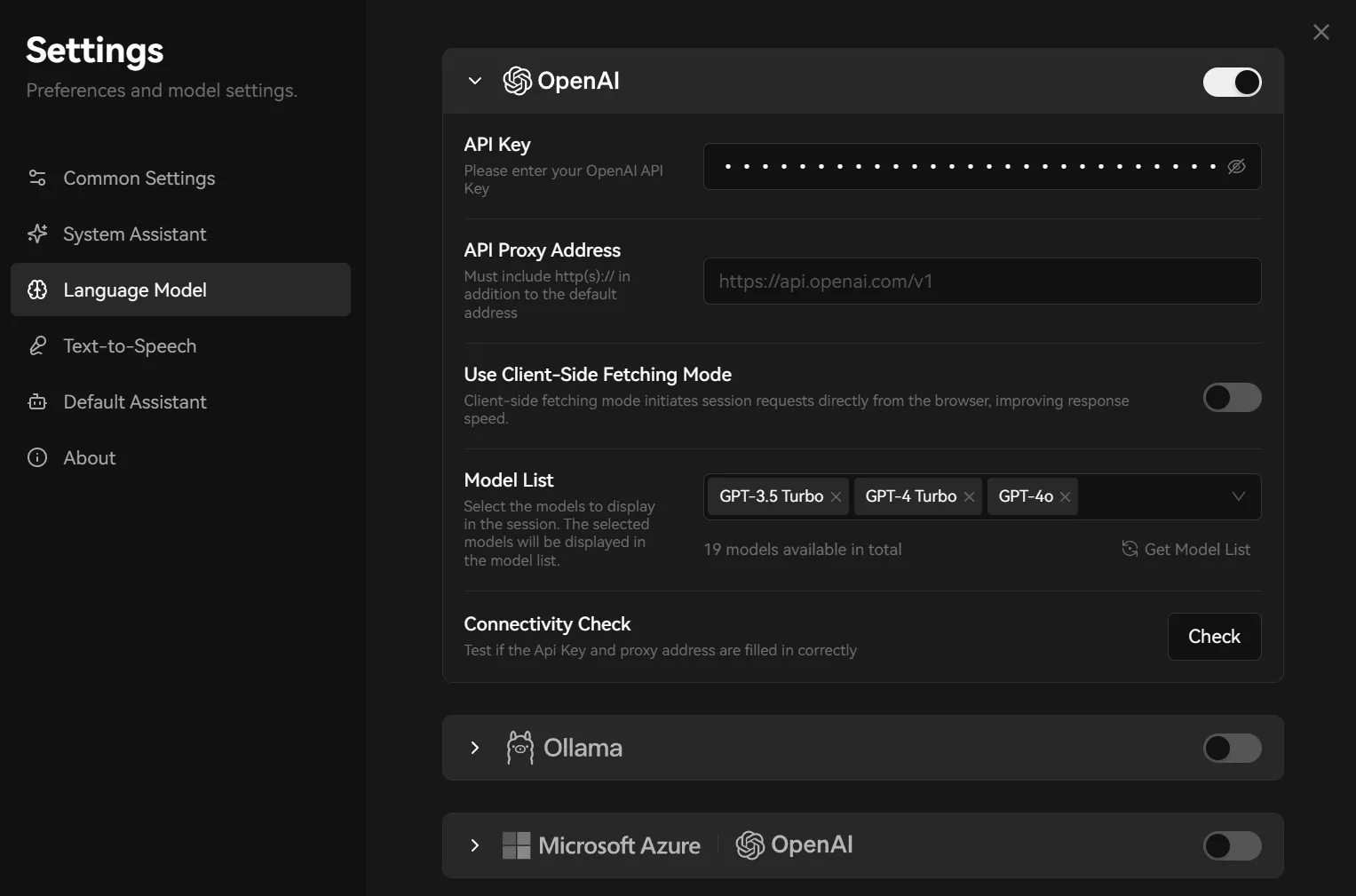
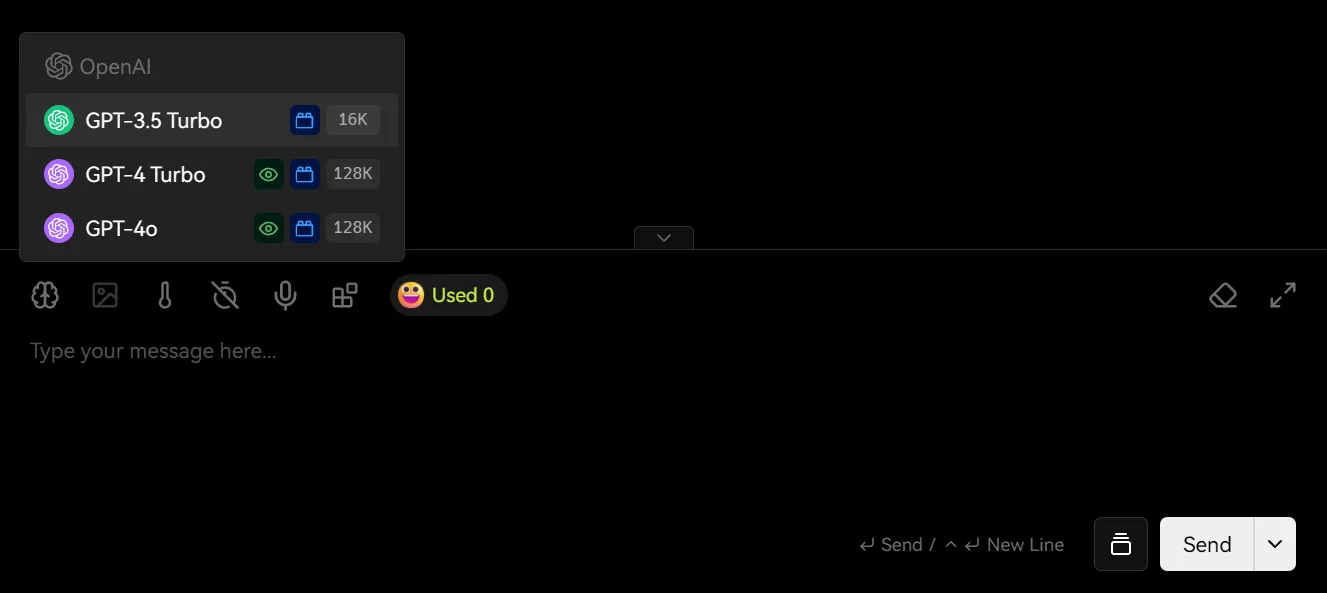
入门用户最容易犯的错,不是“不会配”,而是“OpenAI、Anthropic、Gemini 一起全开”。如果你当前只打算用 GPT 系列,就先只开 OpenAI。
适用于想使用 Claude 3.5、Claude 3.7 等 Anthropic 家族模型的用户。
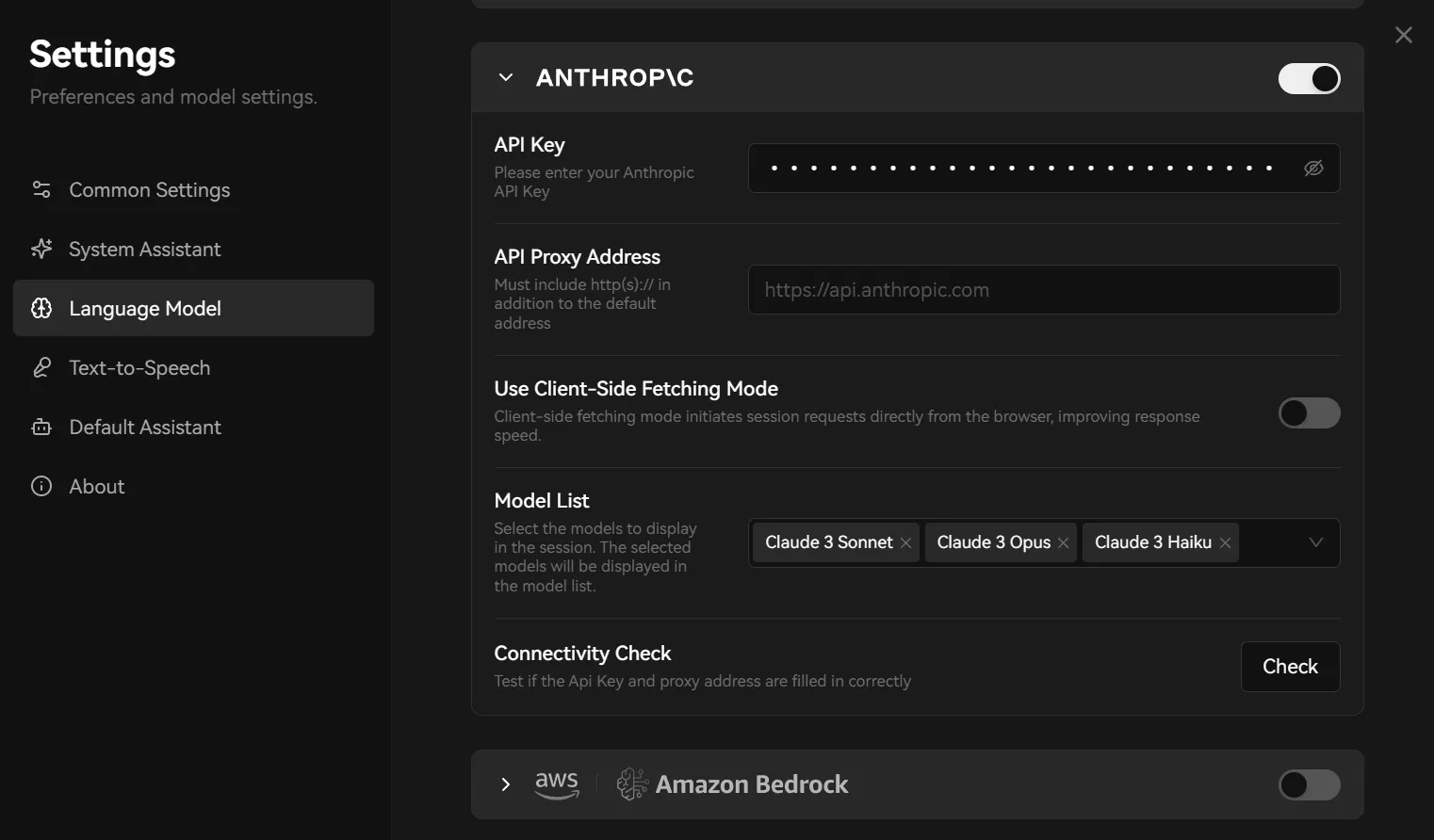
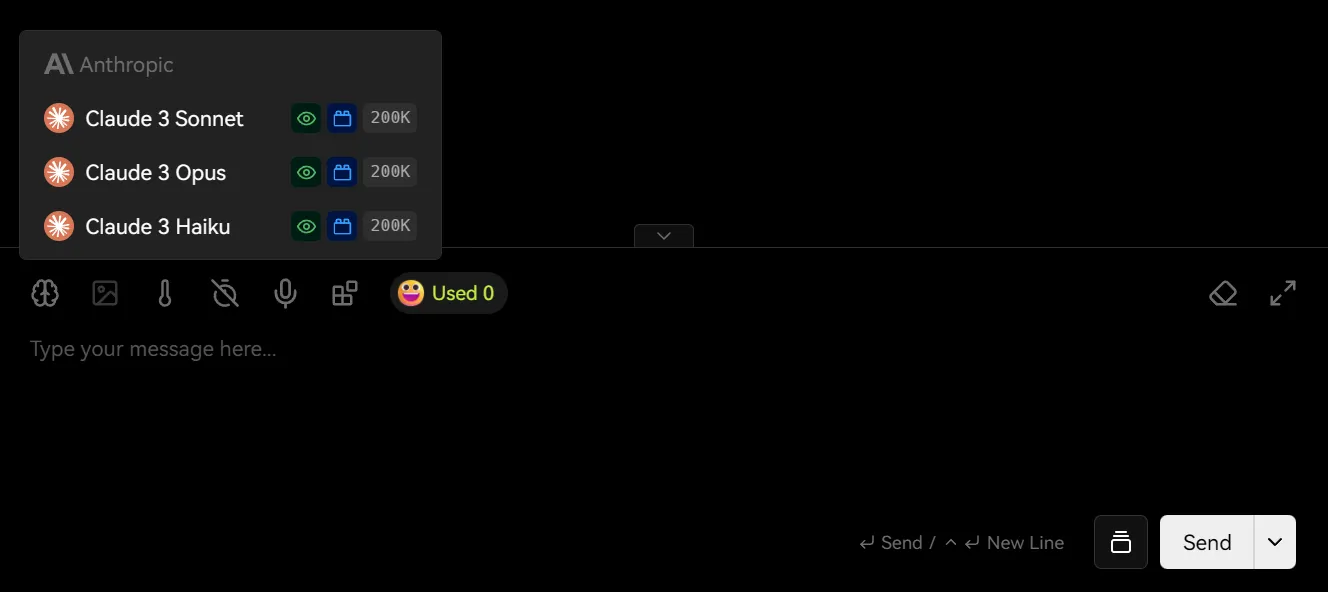
如果你要用 Claude,就按公司来选 Provider:去开 Anthropic Claude。不要因为界面里同时能看到 OpenAI 或 Gemini,就顺手全都开着。
LobeHub 不只有 Web 入口,也提供桌面端和移动端。对初学者来说,建议先用 Web 端把 API 配通,再决定是否安装客户端。
| 入口 | 地址 | 说明 |
|---|---|---|
| 官方 Web | https://app.lobehub.com/ | 官方托管版本,适合直接体验与日常使用。 |
| 本站自建 Web | https://lobehub.saika.pp.ua/ | 可免验证注册,但关闭了市场功能。 |
我这里重新对照了 LobeHub 官方文档与官网分发页。对用户来说,最稳妥的入口是先记住官方总下载页,再按平台选择对应链接。
| 平台 | 官方下载地址 | 说明 |
|---|---|---|
| 总下载页 | https://lobehub.com/downloads | 官方汇总页。桌面端和移动端入口都能从这里进入。 |
| macOS( Apple Silicon ) | https://app.lobehub.com/api/desktop/latest?type=mac-arm | 官方桌面端直链,当前会跳转到最新的 .dmg 安装包。 |
| macOS( Intel ) | https://app.lobehub.com/api/desktop/latest?type=mac-intel | 官方桌面端直链,适合 Intel Mac。 |
| Windows | https://app.lobehub.com/api/desktop/latest?type=windows | 官方桌面端直链,当前会跳转到最新的 .exe 安装包。 |
| Linux | https://app.lobehub.com/api/desktop/latest?type=linux | 官方桌面端直链,当前会跳转到最新的 .AppImage 包。 |
| iOS | https://apps.apple.com/app/id6749615954 | 官方 App Store 页面。 |
| Android | https://play.google.com/store/apps/details?id=com.lobehub.app | 官方 Google Play 页面。 |
官方文档中的“Get LobeHub”页会介绍 Web、桌面端与移动端的适用场景;真正的下载分发则落在官方下载页和官方商店链接上。对初学者来说,优先使用这些官方入口最省事。
如果你只是想先把 API 配起来,建议顺序仍然是:
下面这些功能不需要你一开始就全用上,但知道它们能干什么,会更容易理解 LobeHub 为什么不只是一个“套壳聊天界面”。
| 功能 | 能给用户带来什么 |
|---|---|
| Memory | 让 Agent 逐步记住你的偏好、上下文和工作习惯,减少重复解释。 |
| MCP | 把外部工具、服务和数据接进 LobeHub,让 Agent 不只会聊天,还能调用工具做事。 |
| Skills | 给 Agent 增加具体能力,例如搜索、代码执行、外部 API 调用等。 |
| Agent | 把不同角色拆成不同 Agent,按用途分别配置模型、提示词和工具。 |
| Agent Market | 快速复用社区里已有的 Agent 配置思路,降低上手门槛。 |
| Custom MCP / Skill 管理 | 当你开始需要接自建工具或私有服务时,可以继续扩展,不必换平台。 |
对入门用户来说,建议的使用顺序是:
这一组内容与 Codex 处于同级,专门讲 CC Switch 的安装、首次配置和按应用接入方式。下方条目都是 CC Switch 的子章节。
对于本文档站的目标用户,CC Switch 最值得关注的不是“它支持很多应用”,而是它可以把多个 Provider 配置和多个 CLI 工具的切换动作都集中起来完成。尤其是下面三类使用场景:
| 能力 | 实际意义 |
|---|---|
| 一键切换 Provider | 保存多套配置后,点击即可切换,不用再手改 JSON 或环境变量。 |
| 多应用统一管理 | 同一界面里管理 Claude Code、OpenCode、OpenClaw 等多个 CLI 工具。 |
| 本地代理与健康检查 | 快速验证 API Key、Base URL 和网络可用性,减少盲目排错。 |
| MCP / Skills 管理 | 后续如果你要同步这些增强配置,也可以继续在同一工具中维护。 |
| 备份与恢复 | 切换或迁移机器时更安心,误操作后也更容易回滚。 |
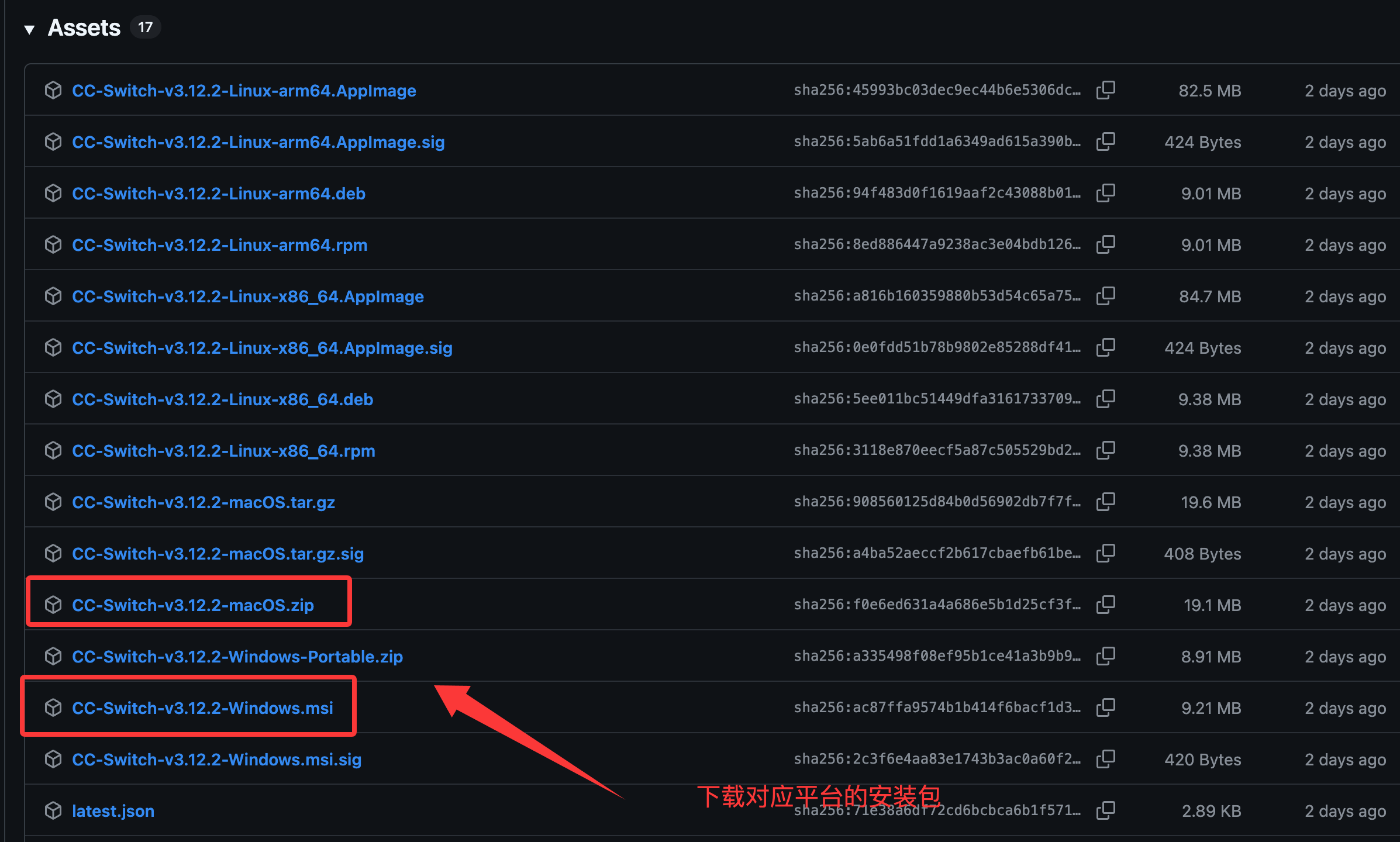
先从官方发布页下载对应平台的安装包,再完成安装。下载入口:GitHub Releases。
| 系统 | 最低版本 | 架构 |
|---|---|---|
| Windows | Windows 10 及以上 | x64 |
| macOS | macOS 10.15 及以上 | Intel / Apple Silicon |
| Linux | 见下方发行版说明 | x64 / arm64 |
| 文件 | 说明 |
|---|---|
| CC-Switch-vX.X.X-Windows.msi | 推荐。MSI 安装包,适合正常安装使用。 |
| CC-Switch-vX.X.X-Windows-Portable.zip | 便携版,解压即用,适合不想走安装流程的场景。 |
安装方式很简单:双击 .msi 安装包,按向导完成安装,然后在开始菜单里搜索 CC Switch 启动即可。
Windows 版已经禁用“一键安装”功能。如果你要管理 Claude Code、OpenCode 或 OpenClaw,请先手动安装这些 CLI,再交给 CC Switch 管理。
如果你习惯用 Homebrew,也可以直接执行:
brew tap farion1231/ccswitch
brew install --cask cc-switch
brew upgrade --cask cc-switch| 发行版 | 推荐格式 | 安装命令 |
|---|---|---|
| Ubuntu / Debian / Mint | .deb | sudo apt install ./CC-Switch-*.deb |
| Fedora / RHEL / Rocky | .rpm | sudo dnf install ./CC-Switch-*.rpm |
| openSUSE | .rpm | sudo zypper install ./CC-Switch-*.rpm |
| Arch / Manjaro / 其他 | .AppImage | 见下方命令 |
chmod +x CC-Switch-*.AppImage
./CC-Switch-*.AppImage下面这套流程适合第一次接触 CC Switch 的用户。你只要按顺序做完,就能把目标 CLI 工具接入进来。
首次启动时,CC Switch 会自动扫描本机已安装的 CLI 工具,并尝试导入已有配置。正常情况下,系统托盘里也会出现 CC Switch 图标。
主界面顶部是应用切换栏。你可以点击对应图标切换当前要管理的工具。对本文档站用户来说,重点建议先关注这三个:
点击右上角的 +,可以从内置预设中选已有服务商,也可以手动新建一条配置。
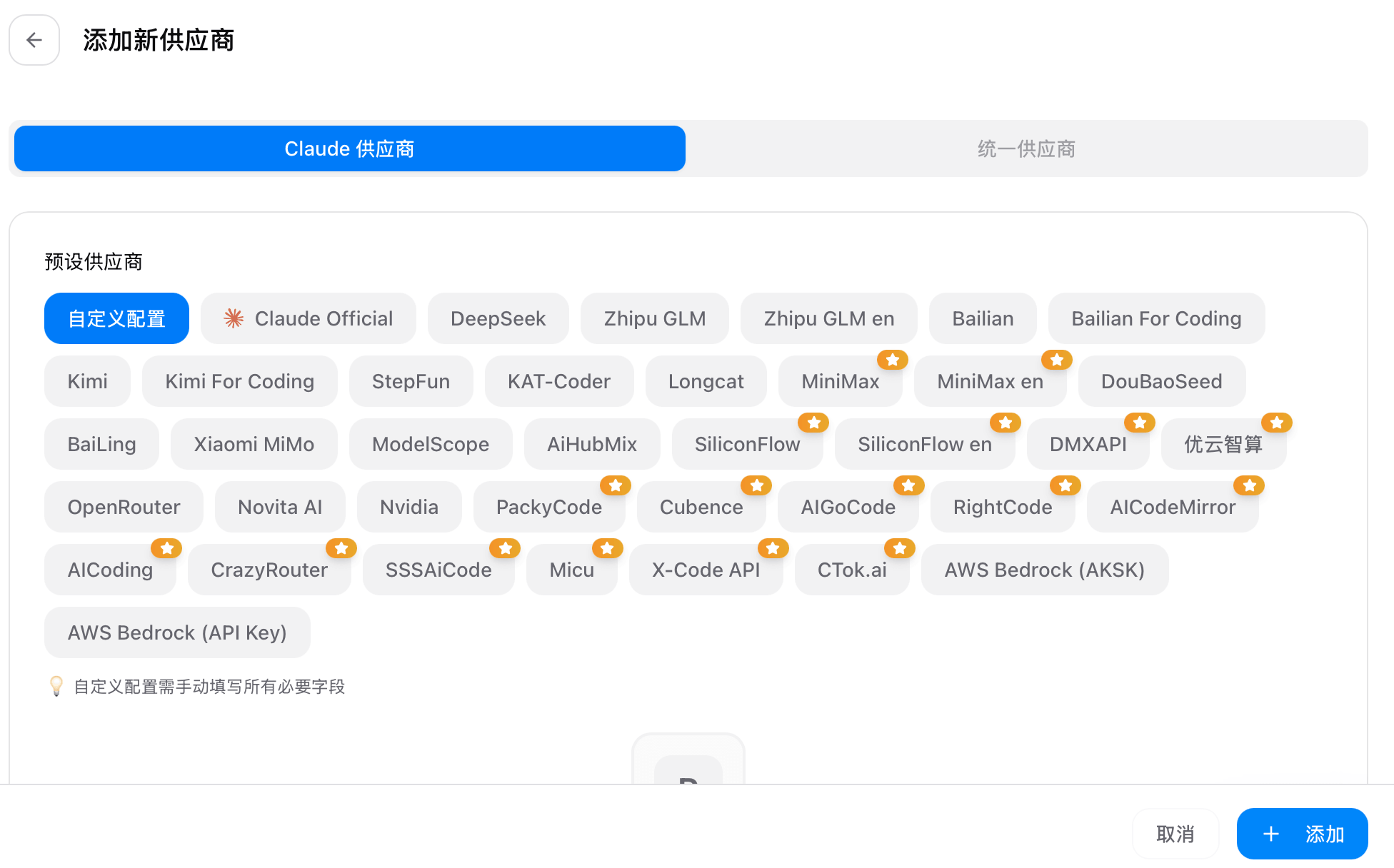
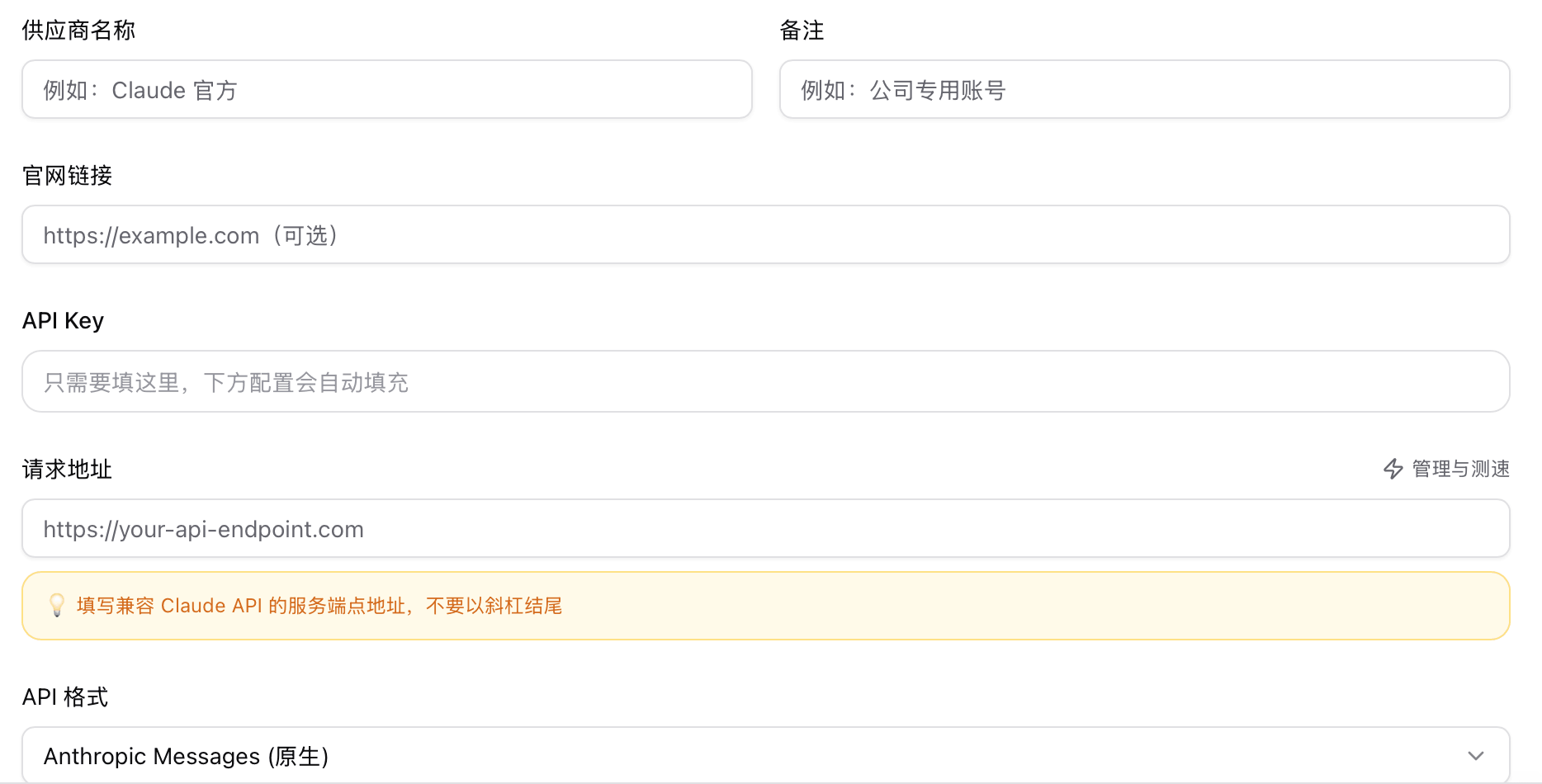
手动填写时,至少要理解下面几个字段:
| 目标应用 | 优先建议的 API 格式 | 使用建议 |
|---|---|---|
| Claude Code | Anthropic Messages | 优先用于 Claude 兼容链路;如果走第三方中转,先确认对方是否完整兼容该格式。 |
| OpenCode | OpenAI Chat Completions | 通常最省事,适合大多数 OpenAI 兼容接口与中转站。 |
| OpenClaw | 按目标 Provider 实际兼容性决定 | 先看服务商文档,再在 CC Switch 里选择对应格式,避免“能连上但请求体不兼容”。 |
| 字段 | 建议理解方式 |
|---|---|
| 名称 | 给这条配置起一个好认的名字,例如“官方 Anthropic”“国内中转 01”。 |
| API Key | 服务商提供的密钥。 |
| Base URL | 如果你走官方接口,可以留官方地址;如果你走中转站或代理,就填对应地址。 |
| 模型 | 默认使用的模型名称。 |
| API 格式 | 根据目标客户端与服务商选择 Anthropic Messages 或 OpenAI Chat Completions 兼容格式。 |
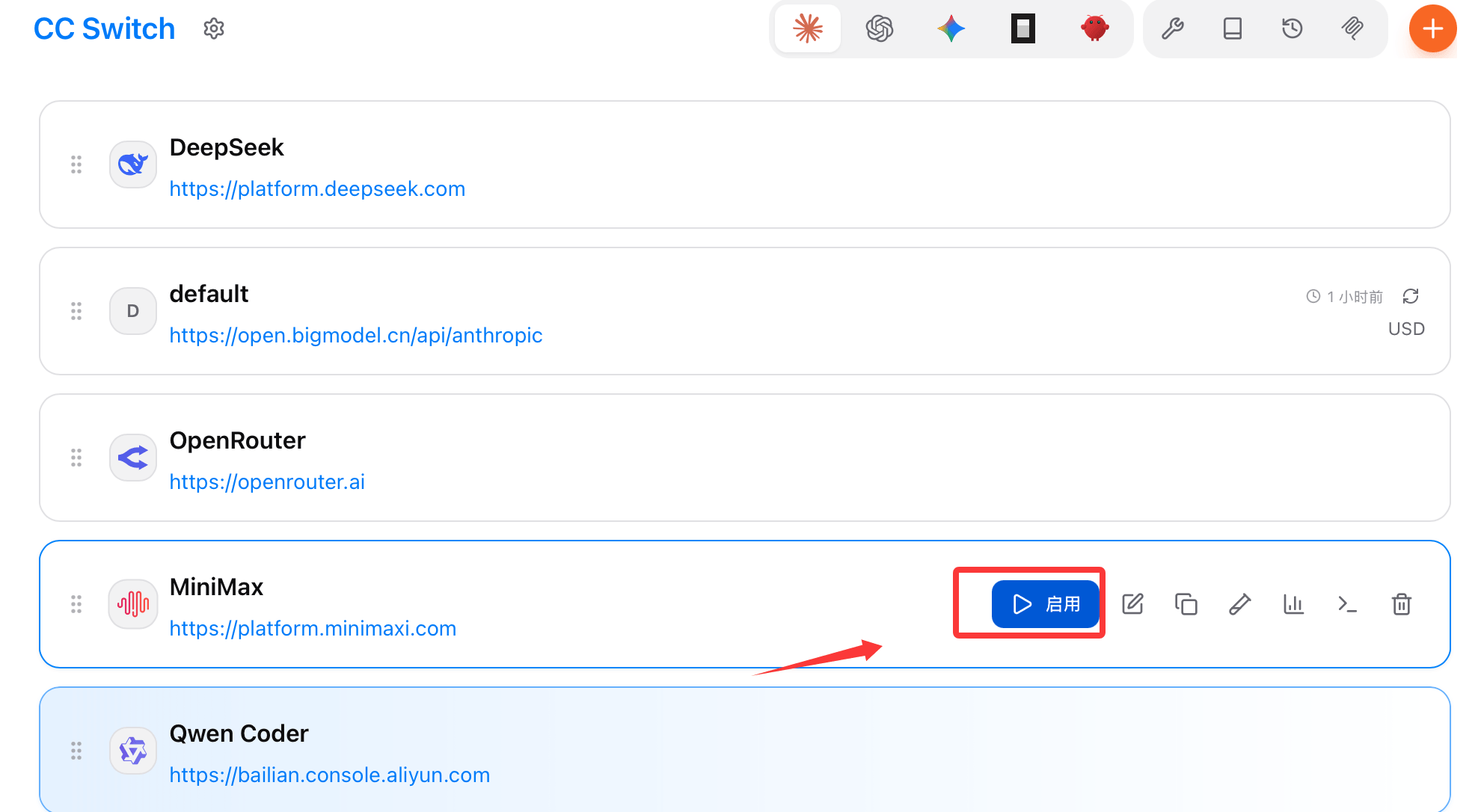
在 Provider 列表中选中目标配置后,点击“启用”。CC Switch 会把对应设置写入你当前选中的 CLI 工具配置里。
如果你不确定 API Key、Base URL 或网络是否正确,先点“健康检查”比直接在 CLI 里报错后再猜原因更高效。
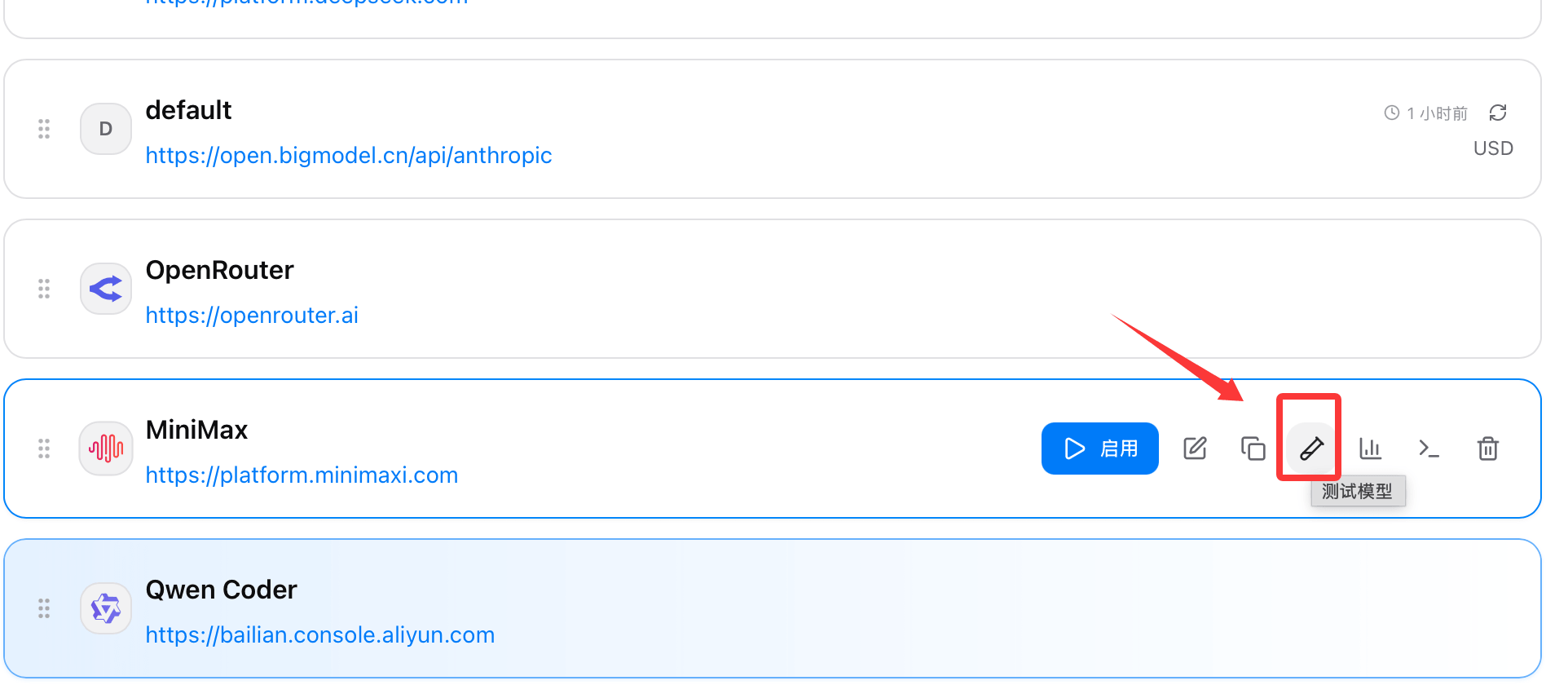
常见判断逻辑:如果健康检查通过,但 CLI 仍然报错,优先排查模型名称、请求格式以及目标 CLI 自身的配置优先级问题。
这是最值得优先讲清楚的场景。很多用户的核心诉求就是:让 Claude Code 能在不同 Provider 之间切换,而不是每次去手改配置。
claude如果你接的是官方 Anthropic,通常只需要正确的 API Key 与模型名;如果你接的是第三方中转站,则要重点确认:
Windows 版 CC Switch 不负责“一键安装” Claude Code。本页默认你已经先手动安装好,再通过 CC Switch 管理它的接入配置。
OpenCode 更适合走 OpenAI 兼容格式。对大多数中转站或代理服务来说,这一类配置通常更直观,也更容易和现有平台对齐。
如果你接的是 OpenAI 兼容接口,通常最容易出错的是这三项:
遇到问题时,不要一次改很多项。建议按“API Key → Base URL → 模型名 → 请求格式”这个顺序逐项排查。
OpenClaw 是 CC Switch 后续新增支持的应用之一。对多客户端并存的用户来说,它的意义在于:可以和 Claude Code、OpenCode 一样,放进同一套切换流程里统一管理。
如果你同时管理多款 CLI,最实用的做法不是每款工具都各配一套完全独立的 Provider,而是先建立一组“可复用 Provider”,再分别切到各个应用启用。这样后面统一更新 Key 或更换中转站时,维护成本会低很多。
对于 OpenClaw,建议你特别留意版本变化。因为它是后续新增支持的应用,一旦上游版本更新较快,配置字段或兼容细节也更可能变化。
如果你只是想把 CC Switch 跑起来,上面的内容已经够用。下面这些进阶功能,适合你开始长期使用之后再看。
如果你已经开始在不同 CLI 中使用 MCP Server,CC Switch 可以把这些配置也集中管理,减少重复维护。
如果你同时在维护 Claude Code 或其他支持相关能力的客户端,Skills 面板可以帮助你统一查看和安装这类增强资源。
当你同时使用多款 CLI 时,会话管理器适合用来集中查历史记录,避免每个工具里来回翻。
建议顺序:先把“安装 → Provider → 切换 → 健康检查”跑通,再去碰进阶功能。对初学者来说,先把核心路径跑通最重要。
如果 CC Switch 看起来已经配置好了,但 CLI 实际运行仍然报错,建议不要盲改,而是按固定顺序排查。
| 现象 | 优先排查 |
|---|---|
| 健康检查失败 | 先查 API Key 是否正确,其次查 Base URL 是否能连通。 |
| 健康检查通过,但 CLI 仍报错 | 优先查模型名称、API 格式,以及该 CLI 是否读取到了最新配置。 |
| 切换 Provider 后没生效 | 确认是否真的点击了“启用”,再重开终端或重启对应 CLI。 |
| 模型找不到 | 对照服务商实际开放的模型名,不要想当然沿用别的平台命名。 |
| 第三方中转站能连但回复异常 | 重点检查请求格式是否匹配,例如 Claude 兼容链路是否真的支持 Anthropic Messages。 |
最容易浪费时间的做法,就是在 API Key、Base URL、模型、请求格式四项都不确定的情况下同时乱改。请始终一次只改一项。